Das LDA-Toolkit (weiterhin in der beta-Version 2.7 unter Windows) ist eine komplexe Toolsammlung, die vor allem für linguistische Diskurs- und Imageanalysen entwickelt wurde, jedoch auch für andere linguistische Fragestellungen von Interesse sein kann. Der Fokus der Tools liegt in der kontrastiven Ermittlung systematischer Ko(n)textprofile als sedimentierte Hinweise für kognitive Konzepte (Stereotype, Frames usw.) in Diskursen.
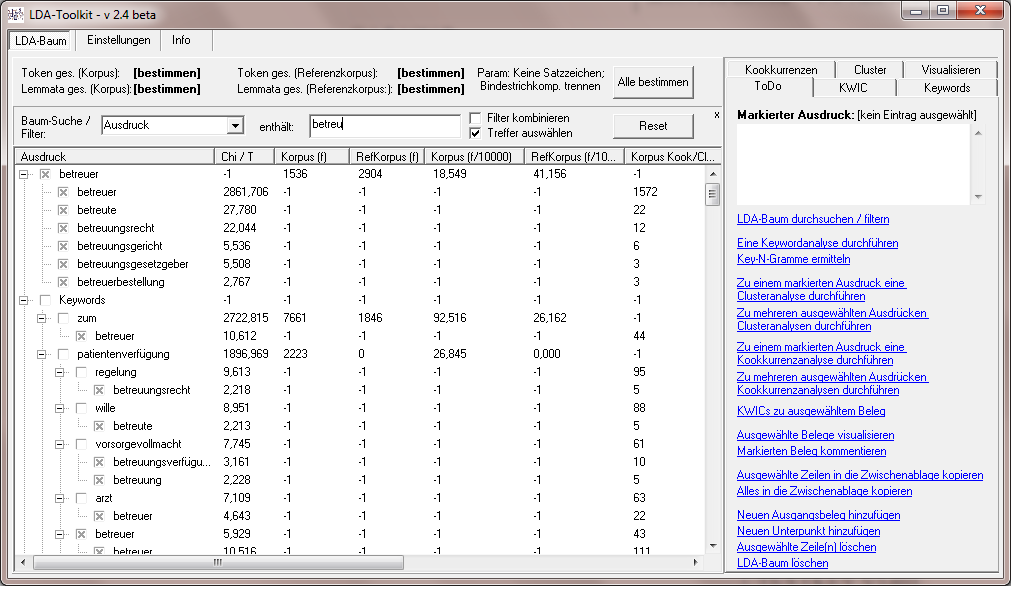
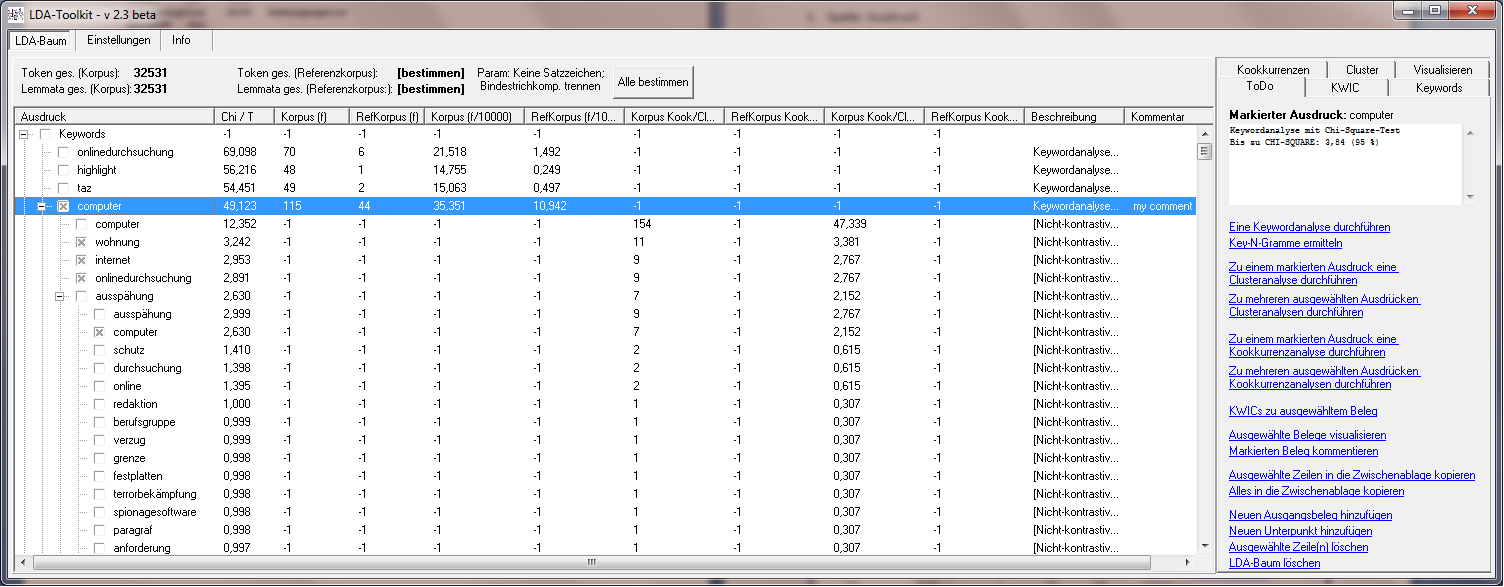

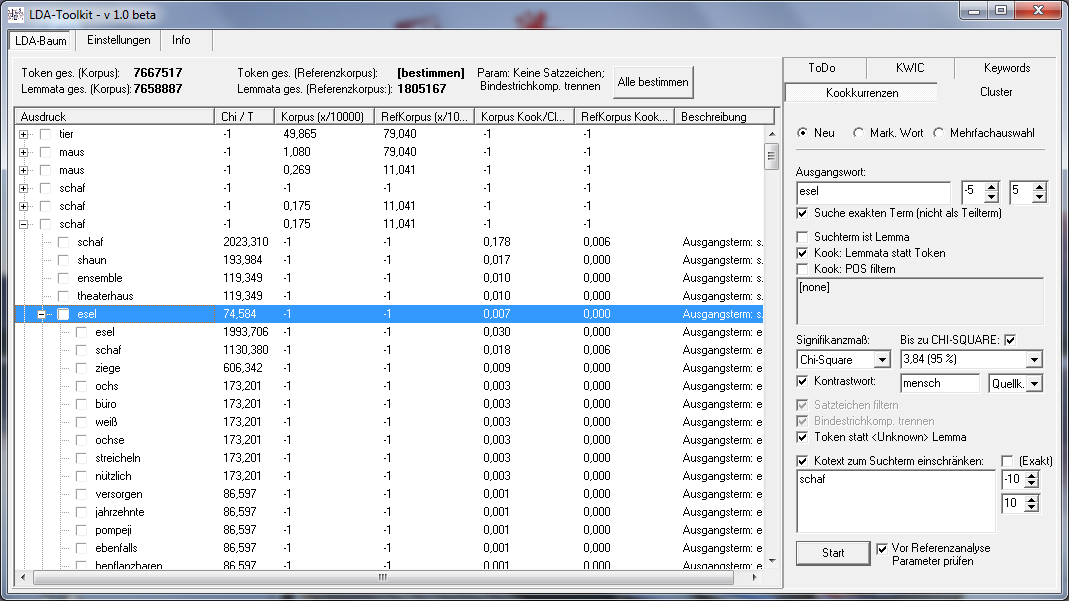
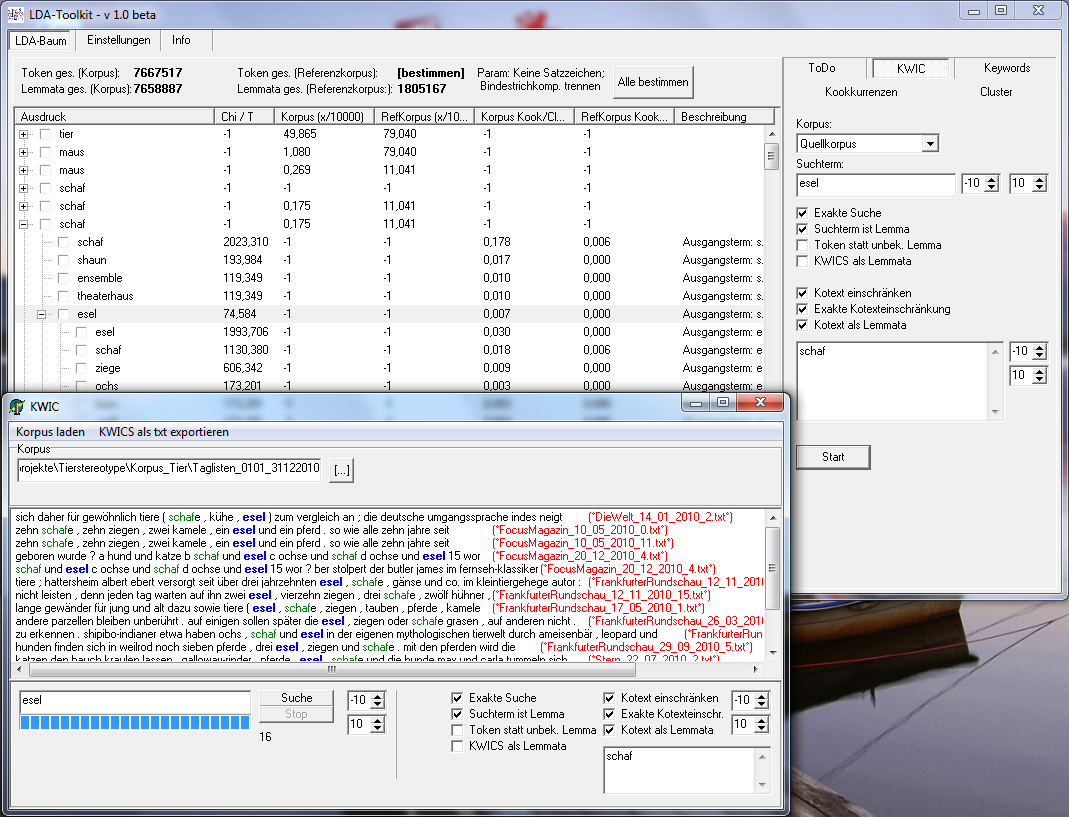
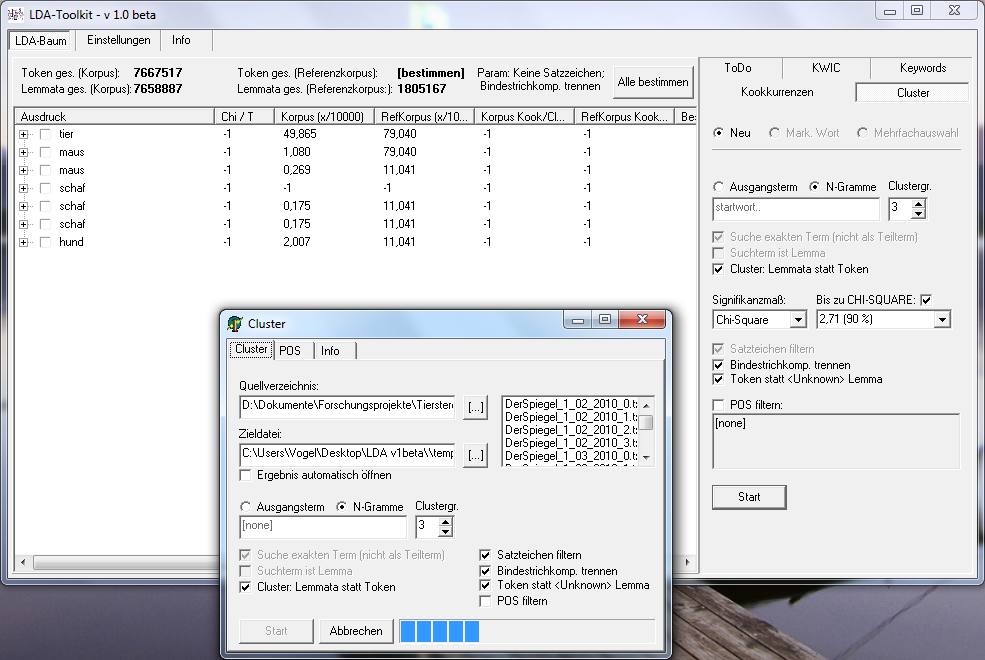
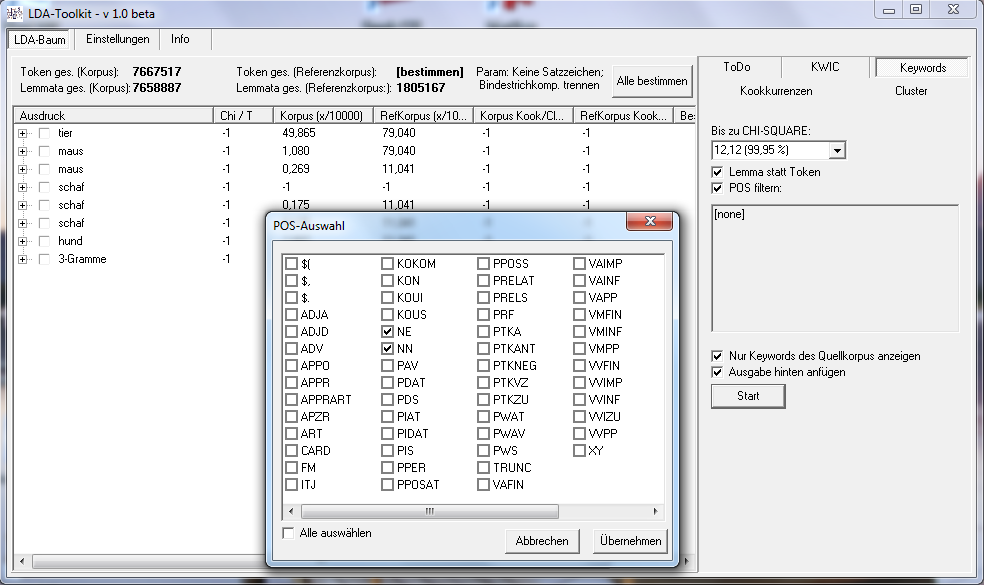
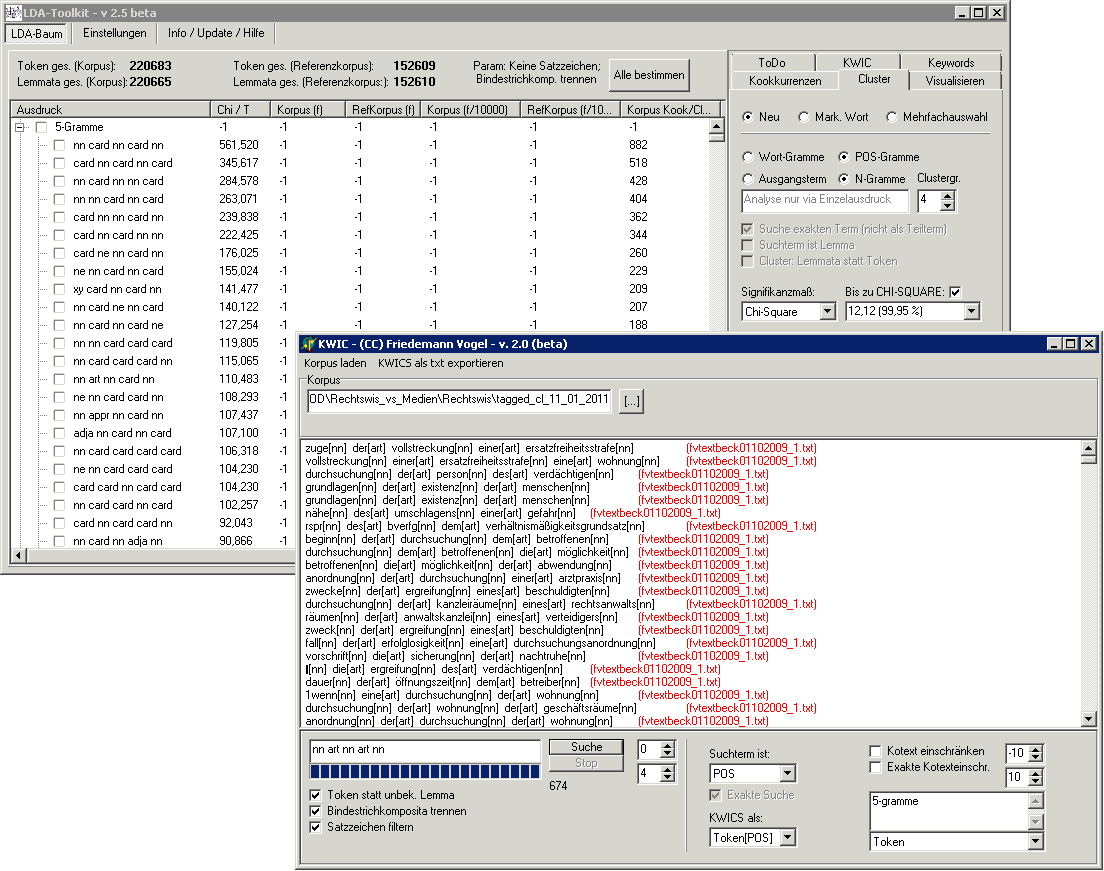
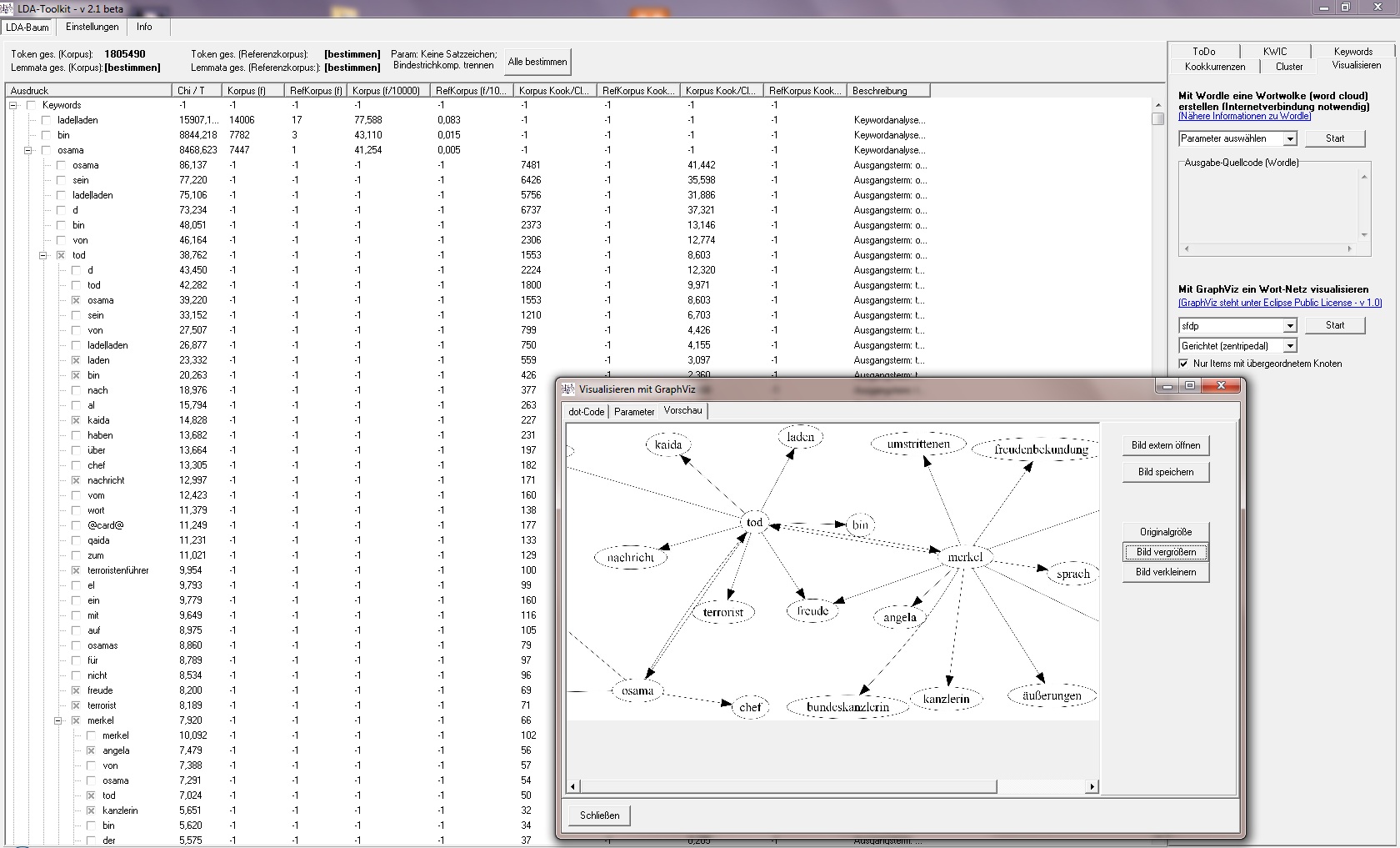
Derzeit stehen folgende Funktionen zur Verfügung:
- Keywordanalyse
- (Key-) Clusteranalyse und (Key-) N-Gramm-Analyse (ab v2.1); Key-POS-Gramme (ab v2.5)
- Kontrastive Kookkurrenzanalyse
- KWICs – „Keywords in Context“ (Zeilenbasierte Darstellung von Suchausdrücken in ihrem Kotext; in diesem Sinne keine eigene ‚Analyse‘)
- Semiautomatische Visualisierungen als Wort-Wolke und Wort-Netz (ab v2.1; derzeit nur eingeschränkt funktionsfähig)
- Kommentarfunktion (ab v2.1)
- Intelligente Such- und Filteroptionen im LDA-Baum (ab v2.4)
Die einzelnen Funktionen können als eigenständige Tools (ohne ihre Zusammenführung und statistische Weiterverarbeitung im Toolkit) verwendet werden. Sie erlauben die Anwendung statistischer Signifikanztests (derzeit: X2und T-Score) sowie die Filterung nach Part-of-Speech-Tags (Wortarten-Spezifikation).
Alle Tools setzen eine vorherige Transformation bzw. ein POS-Tagging der zu ladenden Korpora mit dem Stuttgarter TreeTagger voraus. Außerdem werten die Tools die (derzeit nur deutschsprachigen) Korpora ausschließlich in Minuskeln aus (also keine Unterscheidung von Groß- und Kleinschreibung).
Die Ergebnisse der verschiedenen Analysen werden in einer Baumstruktur dargestellt und können als ‚Arbeitsstände‘ bequem gespeichert bzw. zu einem späteren Zeitpunkt geladen werden.
Dem Programm ist eine kurze PDF-Anleitung bzw. Dokumentation beigegeben (nach der Installation zu finden im Programmverzeichnis [Start / Programme / LDA-Toolkit / Hilfe]).
Ein kurzes Youtube-Video zur Funktionalität des LDA-Toolkit mit erläuternden Kommentaren.
Veröffentlichungen
- 2012. Das LDA-Toolkit. Korpuslinguistisches Analyseinstrument für kontrastive Diskurs- und Imageanalysen in Forschung und Lehre. In Zeitschrift für Angewandte Linguistik (ZfAL), 2012/3, S. 129–165.
Feedbacks
- Rezension von Noah Bubenhofer (Semtracks) zum LDA-Toolkit (05.05.2012)
Updates und Feedback
Das LDA-Toolkit wird derzeit nur sporadisch weiterentwickelt. Über Updates können Sie sich im Nachfolgenden informieren.
Sie haben Kritik, Anregungen oder einen Fehler gefunden? Sie haben das LDA-Toolkit getestet oder verwenden es in Ihrer Forschung oder Lehre? – Dann schreiben Sie mir bitte.
Nutzerlizenz
 LDA-Toolkit von Friedemann Vogel steht unter einer Creative Commons Namensnennung-NichtKommerziell-KeineBearbeitung 3.0 Deutschland Lizenz.
LDA-Toolkit von Friedemann Vogel steht unter einer Creative Commons Namensnennung-NichtKommerziell-KeineBearbeitung 3.0 Deutschland Lizenz.
Für eine kommerzielle Nutzung nehmen Sie bitte Kontakt mit mir auf.
Download
- LDA-Toolkit v2.7 beta (getestet: Win2003, Win XP, Win 7):
- Installationsdatei (Setup.exe – herunterladen und automatisch installieren)
- Zip-Version (herunterladen und entpacken = Installation ohne Admin-Rechte)
Ältere Versionen:
- LDA-Toolkit v2.6 beta (getestet: Win2003, Win XP, Win 7)
- LDA-Toolkit v2.5 beta (getestet: Win2003, Win XP, Win 7)
- LDA-Toolkit v2.4 beta (getestet: Win2003, Win XP, Win 7)
(Anm.: Die Dokumentation ist in dieser Version noch auf dem Stand von v2.3; es fehlen also Hinweise zu neuen Such-, Filter- und Kommenar-Funktionen sowie Ergebnis-Export-Optionen. Die fehlenden Angaben werden spätestens zur Version 2.5 nachgereicht.) - LDA-Toolkit v2.3 beta (getestet: Win2003, Win XP, Win 7)
- LDA-Toolkit v1.1 beta (getestet: Win2003, Win XP, Win 7)
Updates
Neuerungen ab Version 2.7 (03.11.2011):
- Bug gelöst: Fehlermeldung „…ist keine Gleitkommazahl“ (Fehler auf Grund divergierender Formateinstellungen [decimalseparator], je nach Windowskonfiguration)
- Bug gelöst: Analysetools ‚bleiben [scheinbar!] stehen‘: fehlende Übergabe an Application-processmessages (Anzeigefehler)
- Bug gelöst: LDA-Baum löschen erzeugt gelegentlich Fehlermeldung
- Bug gelöst: Wortfrequenzliste(n) nach „Laden“ eines gespeicherten Projektes zurücksetzen
- Einzelne Spalten im LDA-Baum können nun optional angezeigt/verborgen werden
- Schriftgröße im LDA-Baum optional anpassbar.
Neuerungen ab Version 2.6 (23.09.2011)
- Bug gelöst: Fehlerhafte Verarbeitung bei kontrastiven Kookkurrenzanalysen mit bzw. ohne Kontrastwort
- Konkordanzsuche performance-optimiert
- Rechtschreibfehler korrigiert
Neuerungen ab Version 2.5 (20.09.2011)
- Key-POS-Cluster / Key-POS-Gramme (analog zu Keywords bzw. Key-N-Grammen)
- Bug gelöst: Filter und automatische Auswahl nur auf sichtbare Items bezogen
- Erweiterte KWIC-Suche (Konkordanzen als Token, Lemma, POS)
- Automatische (Online-)Versionsprüfung bei Programmstart
Neuerungen ab Version 2.4 (09.09.2011)
- Bug gelöst: fehlerhafte Sonderzeichenverarbeitung für Wort-Wolken
- Komfortablere Suche / Filterung von Datensätzen im LDA-Baum
- Erweiterung der Kommentar-Funktion (Kommentarzuweisung an mehrere Belege gleichzeitig)
- Optionale automatische Kotext-Ergänzung
- Optimierter Datensatz-Export (Spaltenauswahl, kommasepariert)
- Bug gelöst: Temporärer Ordner unter Win7 (fehlerhafte Speicherung / Auswertung von Wortwolken); Fehler tritt nur auf, wenn das LDA-Toolkit in eines der Systemverzeichnisse (\System, \Program Files (x86) u.ä.) installiert wurde.
Neuerungen ab Version 2.1 (05.09.2011)
- Starten mehrerer Instanzen des LDA-Toolkit möglich
- Komprimierte Speicherung
- Neue Registerkarte: Semiautomatische Visualisierung als Wort-Netz (via GraphViz) / Word-Cloud (via Wordle)
- Kommentar-Funktion: Einzelne Belege können kommentiert und anschließend sortiert werden; Suche nach / automatische Auswahl von Kommentaren
- Angabe absoluter Trefferzahlen
- Beschreibung: Kookkurrenz-Count (Token/Type) hinzugefügt
- Bug gelöst: Beschreibung (Type-Token-Count-Beschreibung bei Cluster/N-Grammen war fehlerhaft)
- Nach Arbeitsstand laden: Token/Lemma-Listen neu erstellen (bzw. Token-/Lemma-Listen werden nicht gespeichert)
- KWIC: Optional Bindestrichkomposita trennen
To Do – Geplante Erweiterungen / Bekannte Bugs
Voraussichtlich ab Version 3.1 verfügbar
- Verarbeitung englisch-sprachiger Korpora
- Cloud-Computing: Stellen Sie bestimmte Korpora auf Ihrem lokalen Rechner für Berechnungen in der LDA-Cloud zur Verfügung. Sie erlauben damit anderen WissenschaftlerInnen Ihre Korpora z.B. als Referenzkorpora statistisch verwenden zu dürfen, ohne dass dabei ein kompletter Zugriff auf die Korpusdaten selbst (Texte) freigegeben werden muss.
- Semantic Similarity: Automatische Kontrastierung von Near-Synonyms zur induktiven Diskurs- und Imageanalyse auf Basis von Diskurskarten.
- Schnittstelle zur CWB (insb. für komplexe Konkordanzabfragen)
- Vereinfachte Organisation und Verarbeitung variabler (Teil-)Korpora
- Segmentierung geladener Korpora und kontrastive Frequenzanalysen
- Zusätzlicher Signifikanztest: Log-Likelihood-Ratio (LLR)
- Optimierte KWIC-Suche (Regular Expressions, Sortierfunktionen)
- Anzahl der Texte, in denen Analysetreffer gefunden wurden
- Bug: Wortwolke erstellen